[MXNET-422] Distributed training tutorial #10955
Conversation
There was a problem hiding this comment.
Great tutorial again @indhub! Much needed, we had very little on distributed training with Gluon. What would be really awesome would be training on CIFAR10, and having a graph of validation_accuracy / time for 1 host 4 GPU and 2 hosts 8 GPU. To show the improvement in performance.
docs/tutorials/index.md
Outdated
| @@ -38,6 +38,7 @@ Select API: | |||
| * [Visual Question Answering](http://gluon.mxnet.io/chapter08_computer-vision/visual-question-answer.html) <img src="https://upload.wikimedia.org/wikipedia/commons/6/6a/External_link_font_awesome.svg" alt="External link" height="15px" style="margin: 0px 0px 3px 3px;"/> | |||
| * Practitioner Guides | |||
| * [Multi-GPU training](http://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html) <img src="https://upload.wikimedia.org/wikipedia/commons/6/6a/External_link_font_awesome.svg" alt="External link" height="15px" style="margin: 0px 0px 3px 3px;"/> | |||
| * [Distributed Training](https://github.com/apache/incubator-mxnet/tree/master/example/distributed_training) | |||
There was a problem hiding this comment.
Not a big fan to link to the github repo. I understand the tutorial is not runnable but I would prefer if it was hosted in the tutorials/docs/gluon to avoid fragmentation. Add the right import statements, and put in
runnable:
```python
store = mxnet.kv.create('dist')
```
not meant to be run:
```
for batch in train_data:
train_batch(batch, ctx, net, trainer)
```
That way the code you are using is tested against the CI for correctness.
There was a problem hiding this comment.
I don't think the CI system can currently test distributed training. I think you are trying to say part of the code can be tested. Note that it will only test very trivial parts and Python code that is not tested (which is majority of the code) will lose syntax highlighting which will spoils user experience.
| @@ -0,0 +1,231 @@ | |||
| # Distributed Training using Gluon | |||
There was a problem hiding this comment.
Please move this to docs/tutorials and change this README.md to refer this file instead
There was a problem hiding this comment.
If I move this to docs/tutorials, I can't make it pass the tutorials tests without putting most of the code under "```" instead of "```python". This will remove syntax highlighting and result is bad user experience. If there is a way to whitelist this tutorial from the automated tests, please let me know.
There was a problem hiding this comment.
I only see this block not being able to run in a notebook?
+```python
+for batch in train_data:
+ # Train the batch using multiple GPUs
+ train_batch(batch, ctx, net, trainer)
+```
There was a problem hiding this comment.
Few more blocks:
store = mxnet.kv.create('dist’)
won’t work without a bunch of environment variables being defined. launch.py defines these variables.
trainer = gluon.Trainer(net.collect_params(),
won’t work because net is not defined
print("Total number of workers: %d" % store.num_workers)
won’t work because store cannot be created. See above.
There was a problem hiding this comment.
I see, I just don't like the idea of pointing to a github readme for a tutorial from a UI and UX perspective and also have no test coverage on it. I'll let others weight on it, but if that's the only solution... I'm just not happy with it, considering what happened with the tutorial on the straight dope etc. I wonder if we could work out a specific test case where we run a distributed training in a bunch of docker containers.
There was a problem hiding this comment.
If the concern is about test coverage, can we add distributed_training/cifar10_dist.py to nightly test suite, with some assertion of accuracy on validation set?
|
|
||
|  | ||
|
|
||
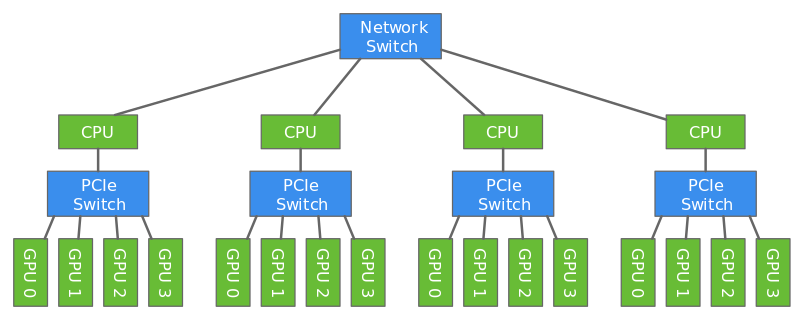
| We will use data parallelism to distribute the training which involves splitting the training data across GPUs attached to multiple hosts. Since the hosts are working with different subset of the training data in parallel, the training completes lot faster. |
|
|
||
| We will use data parallelism to distribute the training which involves splitting the training data across GPUs attached to multiple hosts. Since the hosts are working with different subset of the training data in parallel, the training completes lot faster. | ||
|
|
||
| In this tutorial, we will train a LeNet network using MNIST dataset using two hosts each having four GPUs. |
There was a problem hiding this comment.
could we use CIFAR10 instead? Because multi host multi gpu for mnist is a bit overkill since it trains in 2-3 seconds on a single GPU already?
There was a problem hiding this comment.
Valid point. I'll switch to CIFAR.
| ```python | ||
| store = kv.create('dist') | ||
| print("Total number of workers: %d" % store.num_workers) | ||
| print("This worker's rank: %d" % store.rank) |
There was a problem hiding this comment.
it would be nice to have an example of the output of these functions in the .md file as well
|
|
||
| - `-n 2` specifies the number of workers that must be launched | ||
| - `-s 2` specifies the number of parameter servers that must be launched. | ||
| - `--sync-dst-dir` specifies a destination location where the contents of the current directory with be rsync'd |
| - `-n 2` specifies the number of workers that must be launched | ||
| - `-s 2` specifies the number of parameter servers that must be launched. | ||
| - `--sync-dst-dir` specifies a destination location where the contents of the current directory with be rsync'd | ||
| - `--launcher ssh` tells `launch.py` to use ssh to login to each machine in the cluster and launch processes. |
There was a problem hiding this comment.
login to => login on ?
launch processes => launch the processes ?
|
I'm considering testing this tutorial as part of nightly tests. While we might not have a distributed setup in the CI for testing this, it is possible to run all workers on the same machine. As far as there is enough memory in the GPU for two workers to work simultaneously, it should work and that should be good enough for testing the tutorial. I think something like this should work: |
| @@ -0,0 +1,255 @@ | |||
| # Distributed Training using Gluon | |||
|
|
|||
| Deep learning models are usually trained using GPUs because GPUs can do a lot more computations in parallel that CPUs. But even with the modern GPUs, it could take several days to train big models. Training can be done faster by using multiple GPUs like described in [this](https://gluon.mxnet.io/chapter07_distributed-learning/multiple-gpus-gluon.html) tutorial. However only a certain number of GPUs can be attached to one host (typically 8 or 16). To make the training even faster, we can use multiple GPUs attached to multiple hosts. | |||
| @@ -0,0 +1,231 @@ | |||
| # Distributed Training using Gluon | |||
There was a problem hiding this comment.
If the concern is about test coverage, can we add distributed_training/cifar10_dist.py to nightly test suite, with some assertion of accuracy on validation set?
|
@indhub - Can you update the PR with rebasing and we can get it merged? This tutorial is useful for the users. |
|
@indhub - Thanks for rebasing. Can you please comments on testing this tutorial in nightly test? |
|
Given this is a very useful tutorial and to make distributed training tutorial testing work requires much more work, I'm merging this for now and created a issue to track this #12363 |
* First draft * Python syntax highlighting * Polishing * Add distributed MNIST * rename * Polishing * Add images * Add images * Link to the example python file. Minor edits. * Minor changes * Use images from web-data * Rename folder * Remove images from example folder * Add license header * Use png image instead of svg * Add distributed training tutorial to tutorials index * Use CIFAR-10 instead of MNIST. * Fix language errors * Add a sample output from distributed training * Add the output of store.num_workers and store.rank
Description
Distributed training tutorial
Note: Images might not be visible until dmlc/web-data#67 is merged.
Checklist
Essentials
Please feel free to remove inapplicable items for your PR.